SQL: More Than Databases
Image Credit: Alaa Kaddour
When first getting acquainted with Data Analysis, I knew I had to learn SQL. However, that is exactly what it was: something I had to learn, not something I wanted to learn.
Initially, I thought that SQL only had a narrow use case in managing a database on a computer or server and pulling data to then be analyzed with Python or R, where the real interesting work would happen. Of course, since then I have learned that analysis can be done in SQL without needing to pull the data into another language, and that there are even more uses that had I known back then would have been a huge motivation to focus on SQL.
Spreadsheets
While coding languages will always be more powerful in data analysis, spreadsheets are useful for doing some quick analysis or working with others who don't know how to code. However, some coding functionality would be appreciated at times, and thankfully SQL is easily accessible in Google Sheets. Just use the Query function in a cell, and fill it out:
=QUERY('Sheetname'!DataRange, "SQL query", Header)
=QUERY('Example Data'!A1:E4, "select B where (D>175 and E>53)", 2)
#Don't use the sheetname or '!' if the data is on the same sheet
=QUERY(A1:E4, "select B where (D>175 and E>53)", 2)
Sheets uses a subset of SQL named Query Language, however it is also very similar to base SQL. That’s why ‘FROM’ is not used in the query example. For an overview of Query Language, click here.
Now for Excel users, there is something similar, but it requires more setup, the way to do it with native Excel functionality is to connect it to PowerQuery, and make the SQL query there. Microsoft has an article about that if you are interested here.
Data Viz
SQL is widely used in Tableau, though like Sheets, it is technically a different language-VisQL, but it is functionally very similar. It is used to filter and preprocess data before it gets visualized, but one of my favorite use cases is letting users dynamically select metrics.
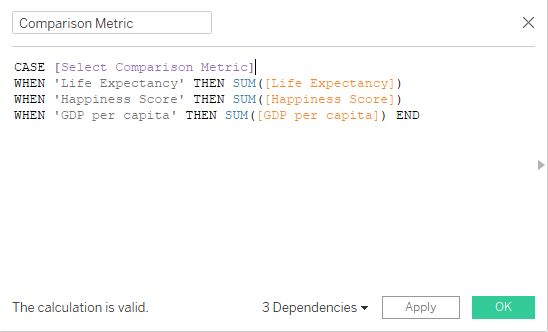
This allows the user-selection to be reflected in the dashboard.
Click here to see this project in action.
For those who are more interested in other data viz tools, it is used in many platforms, from PowerBI to Looker, to Qlik, SQL has a use.
Cloud
Amazon, Google, IBM, Oracle, Snowflake, and undoubtedly more-in short functionally every cloud provider-has product offerings which use SQL to manage relational databases and data warehouses in the cloud.
For example, Google uses SQL in it's BigQuery and Cloud SQL to manage data and even build and deploy ML models with BigQuery and VertexAI, not only using SQL, but adding more functionality that typically is reserved for other languages, allowing more seamless data analysis to be conducted, while leveraging the ever popular strengths of cloud computing.
As cloud computing continues to grow and more and more companies shift to them, SQL will remain useful, for many use case across many platforms.
SQL's Enduring Versatility
Being able to be used in Data Visualization, Spreadsheets, and Cloud Computing, SQL has a place in much of the day to day work in Data Science, and given its Versatility, wide use, and clean syntax that's not changing anytime soon. Despite being made in the 1970s, SQL is a proven pillar of Data Science that is here to stay.
Addendum
Many may be asking why I haven’t included the fact that SQL can be used in Python or R. While that is true, and can help lead to cleaner syntax, there are significant drawbacks that make me hesitant to recommend it. While setup is easy:
#Python
import sqldf
query = '''SELECT * FROM dataframe LIMIT 5'''
print(sqldf.run(query))
#R
library(sqldf)
sqldf("SELECT * FROM dataframe LIMIT 5")
When using this, performance takes a hit. Behind the scenes, the dataframe is being loaded into a temporary SQL database for the query to be ran against, which is going to add overhead. And in addition to that, not all functions work properly, for example, adding or dropping a column doesn’t work. So to work around that, two tables must be made and then merged:
#sqldf
new_df = pd.dataframe({'New_Column': new_column_values})
query = '''SELECT * FROM df LEFT JOIN new_df ON df.index = new_df.index'''
df = sqldf.run(query)
#pandas
df['new_column'] = new_values
The whole point of doing this is to have cleaner and easier to read syntax, and this work around defeats the whole point.
Therefore, while SQL has amazing uses, I don't think this is one of them, and can't recommend using SQL in either Python or R in most circumstances.

